ChatGPT je umjetna inteligencija koja uči od dostupnih podataka. Neki od tih podataka možda se nalaze na vašim web stranicama. Naučite kako možete blokirati ChatGPT i spriječiti ga da koristi sadržaj kojeg ste vi stvorili. Nema garancija da ćete to i uspjeti, ali barem možete pokušati.
AI mašine mogu stvoriti na tisuće tekstova dnevno prateći samo vaše naredbe, no odakle im zapravo znanje?
Large Language Models (LLMs) uče na podacima koji dolaze iz više izvora, od kojih je većih tzv. open source i dozvoljeno je njihovo korištenje za treniranje umjetne inteligencije.
Ovo su samo neki od izvora informacije koje AI koristi za učenje:
- Wikipedia
- Knjige
- Forumi
- Izvještaji
- Web stranice
Postoji dosta web stranica koje besplatno nude ogroman broj informacija, a jedan od njih je i Amazonov Registry of Open Data on AWS.
Baze podataka od kojih uči ChatGPT
ChatGPT se temelji na GPT-3.5, poznatoj i pod nazivom InstructGPT. Ranija verzija GPT-3 koja je temeljena na imititaciji ljudskog ponašanja tj. govora nerijetko je nudila netočne ili uvredljive rezultate nakon davanja naredbi. Model GPT-3 bio je treniran da predvidi sljedeću riječ u rečenici.
InstructGPT je rezultat poboljšanja GPT-3 modela pomoću ljudskog feedbacka. Konkretno, Oen AI koristi tehniku kojoj provjerava svoje učenje tako da se oslanja na povratne reakcije pravih ljudi. I to putem Redddita. Njihova baza podataka WebText2 oslanja se upravo na ovaj ogroman internetski forum.
No oni su za učenje LLM modela koristili više dostupnih baza podataka.
Baze podataka koje su korištene za treniranje GPT-3.5 su:
- Common Crawl (filtrirani)
- WebText2
- Books1
- Books2
- Wikipedia
Od ovih pet baza podataka, dvije su povezane sa sadržajem na internetu:
- Common Crawl
- WebText2
WebText2 je privatna baza podataka tvrtke OpenAI koja je napravila ChatGPT, a svoje podatke vuče iz linkova s Reddita koji imaju barem 3 glasa (upvotes). Ako neki link ima minimalno tri glasa, taj se URL smatra pouzdanim te izvorom kvalitetnog sadržaja. kvalitetan. Upravo su se na ovoj bazi podataka trenirali GPT-3 i GPT-3.5
Kako možete blokirati ovu bazu podataka? Nije poznato.
Ono što se zna jest da ako je link na vašu stranicu završio na Redditu i dobio minimalno 3 glasa, vjerojatno je sadržaj vaše stranice uključen u bazu podataka od koje ChatGPT uči.
Common Crawl je baza podataka koju je napravila neprofitna organizacija Common Crawl.
Podaci iz ove baze podataka dolaze od bota koji pretražuje (crawla) cijeli Internet. Podatke koje organizacije žele koristiti spremaju se i zatim čiste od spama.
Ima bota Common Crawla je CCBot.
CCBot prati protokol robots.txt datoteke pa ga je moguće i blokirati. Robots Exclusion Protocol ili Robots.txt je datoteka na web stranici koja govori tražilici da ignorira određene dijelove web stranice. Primjerice, robots.txt file sprečava Googleov da indeksira neki sadržaj na vašim web stranicama i prikaže među rezultatima pretrage. Najčešće blokiramo stranice poput administratorskih dijelova, “Dodaj u košaricu” ili pak Politiku kolačića.
Valja napomenuti da ukoliko je CCBot već ranije pristupio vašoj stranici, vjerojatno je već indeksirao i pohranio u razne baze podataka dostupne informacije i tu ne možete ništa. Možete ga blokirati da ne koristi nove informacije na vašim web stranicama.
Dodajte ovo u robots.txt datoteku:
User-agent: CCBot
Disallow: /
Nadam se da će vam ovo pomoći ako ne želite da se u budućnosti vaš autorski sadržaj koristi za treniranje umjetne inteligencije. Pitanje autorskih prava i etičnosti korištenja tuđeg sadržaja za učenje umjetne inteligencije još su ostala neodgovorena.
VEZANO:
Najnoviji članci

SEO vs kreativno pisanje tekstova za web – razlika je ogromna!
Pisanje za web nije isto kao i pisanje za offline medije. Dok u offlineu bolje prolazi kreativno pisanje, online on znači propuštene prilike.
 26 svibnja, 2026
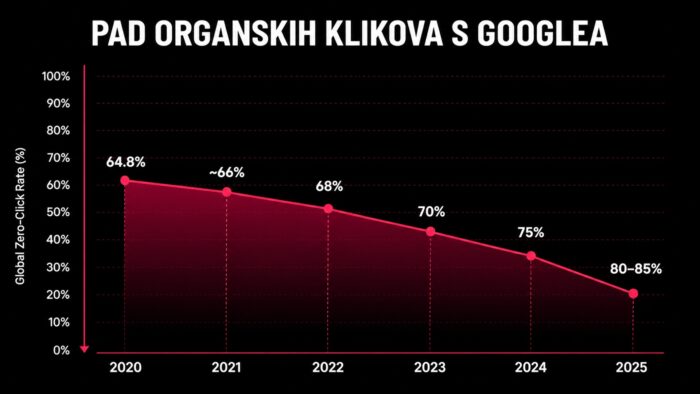
26 svibnja, 2026Ogroman pad prometa s Googlea: 83% ljudi ne klikne na ništa ako im se otvori AI prozor
U svijetu interneta vidimo ogroman pad web prometa. AI platforme ubijaju klikove. Cijeli SEO i izdavački ekosustav je pod rizikom
21 svibnja, 20268 načina kako završiti na Google Discoveru (i dobiti do 100.000 pregleda)
Google Discover je personalizirani feed sadržaja za korisnike android uređaja koji može značiti jako puno za povećanje prometa prema vašim web stranicama.
07 svibnja, 2026